In an earlier post, we wrote about how 51% of web traffic is now non-human — and how AI bots and agentic browsers are corrupting analytics metrics that were never built to handle them. Since then, the problem has evolved faster than most teams anticipated.
The first wave of AI traffic — the scrapers training large language models — is now a known quantity. But a second wave has arrived: LLM-powered crawlers that operate on behalf of real users in real time. These aren't just scrapers. They're question-answering engines, research agents, and AI browsing tools that visit your site, read your content, and report back — without your analytics seeing any of it.
"Your bot filters know what Googlebot looks like. They have no idea what GPT-4o web search looks like."
That gap is growing. And the sites that understand LLM crawlers — what they are, how they behave, and how to detect them — will have a structural advantage in the AI-native web that's rapidly becoming the default.
What LLM Crawlers Actually Are
The term "LLM crawler" covers several distinct types of non-human visitors that have emerged as AI assistants have gone mainstream. They're related but meaningfully different from each other — and from the traditional bots your current filters are designed to catch.
1. Training Data Scrapers (The First Wave)
These crawl the web systematically to collect text for training or fine-tuning AI models. GPTBot (OpenAI), ClaudeBot (Anthropic), Google-Extended, CCBot (Common Crawl) — these are the most visible, as most declare themselves through user-agent strings and respect robots.txt when asked.
They're relatively easy to detect and block. Many sites have already updated their robots.txt to exclude them. The problem: they represent only a fraction of AI traffic.
2. Real-Time Retrieval Crawlers (The Second Wave)
These visit your site on demand, in real time, to answer specific user questions. When someone asks Perplexity "What are WysLeap's pricing plans?" or asks ChatGPT to "summarise the latest articles from [your blog]," a crawler fetches your page, processes it, and returns an answer to the user — who never visits your site in their browser.
Key characteristic: these crawlers are triggered by user intent, visit specific pages, and fetch only what they need. Their traffic pattern looks nothing like systematic scrapers — which is exactly why they evade traditional bot filters.
3. Agentic Browsers (The Third Wave)
These are AI systems that browse the web on behalf of users to complete tasks. Unlike retrieval crawlers that just fetch pages, agentic browsers can navigate, click, fill forms, and interact with dynamic content. Tools like Perplexity Comet, browser-use, Playwright-based AI agents, and increasingly, operating-system-level AI assistants fall into this category.
They're the hardest to detect because they often execute JavaScript, render pages fully, and exhibit behaviour patterns that overlap with legitimate human browsing.
The Scale Is Already Significant
Analysis of server logs across publisher sites in early 2026 shows LLM-related crawl requests running at 15–25% of total traffic on content-heavy sites. For SaaS product sites with detailed feature documentation and pricing pages, the share is even higher.
Almost none of this is captured in standard analytics dashboards. It's not a niche edge case — it's a structural gap in how the web is currently measured.
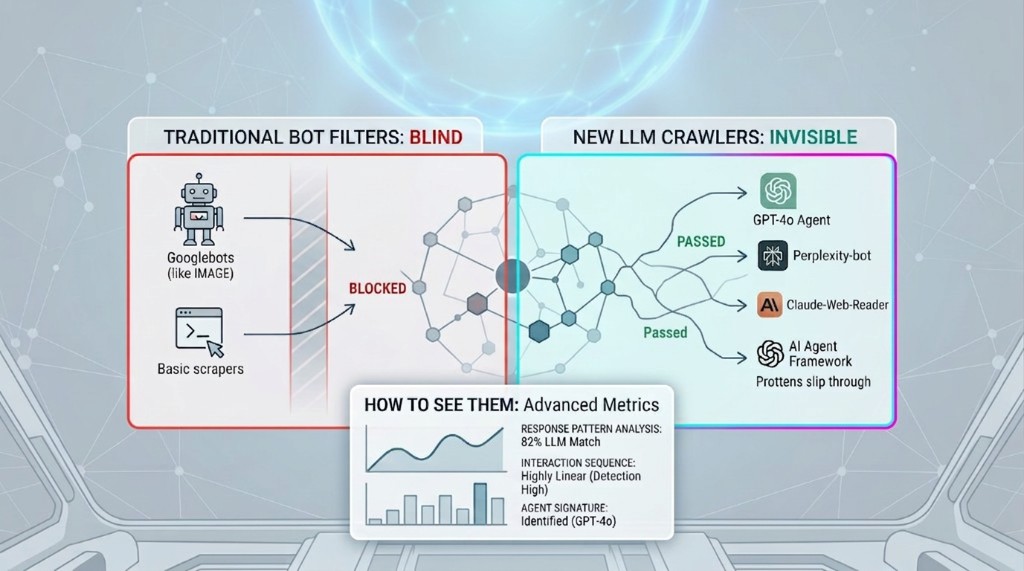
Why Your Existing Bot Filters Can't Catch Them
Traditional bot detection was designed for a different threat model. Understanding why it fails on LLM crawlers requires understanding exactly what it was built to catch.
User-Agent Blocklists Don't Scale Anymore
Traditional bot filters maintain lists of known bad user-agent strings. This works when there are dozens of known scrapers, each with a consistent signature. It doesn't work when there are thousands of AI frameworks, many of which rotate user agents, spoof browser signatures, or simply use legitimate browser user-agent strings.
GPTBot declares itself. So do ClaudeBot and Googlebot-Extended. But a custom agent built on Playwright or Puppeteer may present as Chrome 131 on macOS with no distinguishing characteristics at all. Blocklists catch the honest actors while missing the ones that matter.
Client-Side Analytics Scripts Don't Run
The majority of analytics platforms — including Google Analytics 4 — are client-side. They rely on a JavaScript tag executing in the visitor's browser. When a retrieval crawler fetches a page without executing JavaScript (which many do, by design, for efficiency), the analytics tag never fires. The visit is completely unrecorded.
This is the invisibility problem: not that these crawlers are hard to detect, but that the detection mechanism itself doesn't run when they arrive.
Behavioral Heuristics Were Trained on Old Patterns
Traditional bot detection looks for patterns like: visits too many pages too fast, stays zero seconds, comes from suspicious IP ranges, doesn't accept cookies, has no mouse movement. LLM retrieval crawlers violate none of these. They visit specific pages, spend a normal amount of "time" fetching them, come from cloud provider IP ranges, and navigate sensible paths.
They look, to old detection models, like a careful human browsing from a cloud server. Which is, in a sense, exactly what they are.
The Robots.txt Problem
Robots.txt is the web's social contract: crawlers that respect it identify themselves and follow your access rules. The problem is compliance is voluntary. OpenAI, Anthropic, and a handful of large players respect robots.txt. The ecosystem of third-party AI tools, open-source agent frameworks, and enterprise AI platforms that are now building on top of these models largely don't.
You can opt out of GPTBot. You cannot opt out of a developer's custom AI agent built on GPT-4o that browses using a Chrome user-agent.
How to Actually Detect LLM Crawlers
Detection requires combining multiple signals that, individually, are weak — but together, create a reliable fingerprint. Here's the layered approach that works in practice.
Layer 1: Server-Side Request Analysis
This is where detection has to start — before client-side JavaScript ever runs. Examine raw HTTP request headers for signals that correlate with automated fetching:
- Accept-Language header: Bots frequently send
Accept-Language: *or a minimal set. Humans have specific language preferences. - Missing or minimal Sec-Fetch headers: Modern browsers send a rich set of Sec-Fetch-* headers. Many crawlers omit these entirely.
- No Accept-Encoding diversity: Browsers accept multiple compression schemes. Minimal bots often send only
Accept-Encoding: gzip. - IP range analysis: Cloud provider IP ranges (AWS, GCP, Azure) are overrepresented in LLM crawler traffic versus human traffic.
Layer 2: JavaScript Execution Probe
The cleanest signal: does JavaScript run? Embed a lightweight, non-blocking beacon in your page that fires on load. Requests that arrive at your server without a corresponding beacon hit within a short window (2–5 seconds) are almost certainly non-JS-executing crawlers.
// Minimal JS beacon — add to page layout
fetch('/api/telemetry/js-probe', {
method: 'POST',
body: JSON.stringify({ url: location.href, ts: Date.now() })
});
Layer 3: Behavioural Fingerprinting
For LLM crawlers that do execute JavaScript, detection shifts to behavioural signals:
- No mouse movement or touch events: Humans move their cursor before clicking. Headless browsers and agents typically trigger clicks without prior mouse movement events.
- Abnormal timing patterns: Humans scroll, pause, read, scroll again. Crawlers that render pages typically scroll to a fixed depth immediately.
- Navigator API anomalies:
navigator.webdriveris true for browser automation frameworks unless explicitly patched. - Screen dimension consistency: Agentic browsers often run in default headless viewport sizes (1280x720, 1366x768) with unusual pixel ratios.
Layer 4: ML-Based Anomaly Detection
Individual signals can be individually weak — LLM crawlers are getting better at mimicking human behaviour. The strongest detection approach combines all signals into an ML model that:
- Learns the normal distribution of your site's human traffic (not a generic model)
- Identifies deviations from that distribution as anomaly scores
- Updates continuously as new crawler patterns emerge — so detection improves as the threat evolves
- Can cluster anomalous traffic into named patterns (e.g., "Perplexity fetch pattern," "headless Chrome agentic," "unknown retrieval crawler")
This is the core of WysLeap's auto-bot-discovery system — a self-learning detection layer that identifies new bot patterns from behavioural anomalies and continuously refines its accuracy through feedback.
What to Do Once You Can See Them
Detection is only the first step. What you do with LLM crawler traffic depends on what type it is and what your goals are. The right response is not always "block."
For Training Scrapers: Robots.txt + Licensing
If your primary concern is your content being used to train AI models without compensation, robots.txt directives for known crawlers (GPTBot, ClaudeBot, CCBot) are the first line of defence. Beyond that, content licensing discussions with AI companies are becoming increasingly viable — and knowing exactly which crawlers are accessing your content and how frequently puts you in a much stronger negotiating position.
For Real-Time Retrieval: Measure, Then Decide
Before blocking real-time retrieval crawlers, consider what they're actually doing. If Perplexity is fetching your pricing page ten times a day in response to user queries, those queries represent genuine commercial intent from humans who could become customers. Blocking the crawler may redirect that intent to a competitor's pricing page instead.
The more strategic move: optimise your content for AI retrieval, ensure your most important information is in the HTML (not behind JavaScript rendering), and monitor which pages get fetched most. Those pages are surfacing in AI answers — they deserve your attention.
For Agentic Browsers: Intent-Based Classification
As noted earlier, 87% of AI agent page visits are product-related — meaning they represent a human with genuine purchase intent who has delegated research to an AI assistant. Blanket blocking loses those leads.
A better approach: classify agentic traffic separately, exclude it from your human-audience metrics (so your analytics remain clean), but don't block it from accessing your content. Treat agentic visits as an engagement signal — if an AI agent is visiting your pricing page on someone's behalf, that someone is worth understanding.
The Metrics to Track
- LLM crawler share of total traffic — trending up is expected, but sudden spikes may indicate targeted scraping
- Top pages by LLM fetch volume — tells you which content is being surfaced in AI responses
- Crawler type breakdown — training scrapers vs. real-time retrieval vs. agentic, treated differently
- Human-only traffic trend — your actual audience, separated from machine traffic
- New bot pattern emergence — novel traffic signatures you haven't seen before
Why Static Lists Will Always Lose — and What Wins Instead
The LLM crawler landscape changes every few months. New AI tools launch. Existing ones update their user agents. Enterprise customers build internal agents on top of public APIs. Open-source frameworks proliferate.
Any detection approach based on a static blocklist is already behind. By the time you add a new crawler signature to your filter, it's been joined by a dozen variants you haven't seen yet.
The Only Sustainable Approach: Behavioural ML That Adapts
A detection system that learns what your human traffic looks like, continuously updates that model, and identifies deviations — without needing to know the name of the crawler producing them — is fundamentally more durable than any static approach.
This is why WysLeap's bot detection is built on adaptive ML rather than blocklists. When a new crawler pattern appears — even one we've never seen before — the anomaly detection flags it, the pattern is learned, and the model improves. No manual update required. No lag between new threat and detection.
The Three-Layer Architecture That Works
- Server-side collection — capture all traffic before any JavaScript runs, so nothing is invisible by default
- Multi-signal classification — combine header analysis, JS execution probes, and behavioral fingerprinting to classify each visitor
- Self-learning anomaly detection — continuously identify new patterns, update the model, and improve accuracy without manual intervention
The result is a system that gets better at detecting LLM crawlers over time — not worse, as blocklists become stale.
The Taxonomy Cheat Sheet
| Crawler Type | Detectable by UA? | Runs JS? | Risk to Metrics | Recommended Action |
|---|---|---|---|---|
| Training scrapers (GPTBot, CCBot) | Often yes | No | Content theft | Block via robots.txt |
| Real-time retrieval (Perplexity, Bing AI) | Sometimes | Rarely | Invisible in analytics | Measure, then decide; optimise content for AI |
| Custom agents (Playwright, browser-use) | Rarely | Sometimes | Corrupts metrics | ML behavioural detection required |
| Agentic browsers (Comet, Gemini) | No | Yes | Inflates engagement | Classify separately; don't block |
See Every Bot That's Hitting Your Site
WysLeap's self-learning bot detection automatically discovers new patterns — including LLM crawlers your current filters have never seen. Get clean human-only metrics alongside full bot visibility, with zero manual configuration.
Siva J.P.
Privacy Research Lead at WysLeap